DDoS-Angriffe nehmen sowohl an Intensität als auch an Präzision rapide zu. Sie sind mittlerweile kürzer, gezielter und werden zunehmend durch künstliche Intelligenz generiert.
Link11 Network DDoS Protection war seit jeher ein starker und verlässlicher Standard für Unternehmen, die ihre Netzwerkinfrastruktur absichern möchten. Doch die Anforderungen moderner Unternehmensnetzwerke haben sich verändert. Angreifer verfeinern ihre Strategien kontinuierlich. Und das Letzte, was Ihr Team braucht, ist der Druck, mitten in einem laufenden Angriff ständig neu justieren zu müssen.
Deshalb haben wir als direkte Antwort auf die sich wandelnden Mitigation-Anforderungen moderner Unternehmensumgebungen unser Angebot für Network DDoS Protection deutlich weiterentwickelt.
Dieser Artikel zeigt auf, was sich in der DDoS-Bedrohungslandschaft verändert hat und was diese Veränderungen für Ihre Schutzstrategie bedeuten.
Dual-Stack-Schutz: Abdeckung von IPv4 und IPv6
Mit der wachsenden Verbreitung von IPv6 operieren moderne Umgebungen zunehmend über IPv4- und IPv6-Netzwerke hinweg. Diese Flexibilität wird von unseren Kunden zwar sehr geschätzt, sie verändert jedoch die Schutzanforderungen. Wenn IPv6-Traffic erreichbar ist, aber nicht mit der gleichen Präzision wie IPv4 geschützt wird, können Angreifer diese Lücke nutzen, um Abwehrmechanismen zu umgehen und Dienste zu stören.
Die neue Generation von Link11 Network DDoS Protection schließt diese Lücke vollständig. Unternehmen müssen Ihre IPv6-Infrastruktur nicht mehr separat absichern oder mit unterschiedlichen Schutzstufen arbeiten. Ihr gesamtes Netzwerk wird mit derselben Erkennungstiefe, Mitigation-Geschwindigkeit und Kapazität geschützt, unabhängig davon, ob ein Angriff auf IPv4 oder IPv6 abzielt.
Erfahren Sie, wie die neue Network DDoS Protection Sie noch effektiver schützt
Schnellere Mitigation, IPv6-Parität, mehr Transparenz und deutlich weniger manueller Aufwand.
Adaptive Mitigation: Jeder Angriffsvektor erhält seine eigene Antwort
Herkömmliche DDoS-Mitigation beginnt häufig mit einer einfachen Prämisse: ungewöhnlichen Traffic erkennen, einen Alarm auslösen und eine breit angelegte Mitigation-Maßnahme anwenden.
Dieser Ansatz wehrt zwar Angriffe ab, mangelt jedoch häufig an Präzision, wenn es darum geht, sich rasch entwickelnde Angriffe abzuwehren. Wenn zudem zu weitreichende Abwehrmaßnahmen ergriffen werden, kann neben dem bösartigen Datenverkehr auch legitimer Datenverkehr beeinträchtigt werden. Dies kann für Unternehmen zu schwerwiegenden Reputationsschäden sowie zu Umsatzverlusten führen.
Die nächste Generation von Link11 Network Protection verfolgt einen anderen Ansatz. Ihre adaptive Mitigation-Engine analysiert jeden einzelnen Angriffsvektor und entwickelt eine gezielte Antwort auf den Angriff. Volumetrische Angriffe werden getrennt von protokollbasierten Angriffen oder Amplification-Vektoren behandelt.
Das bedeutet eine deutlich höhere Präzision bei der Mitigation selbst komplexester Angriffe und weniger False Positives. Legitimer Traffic bleibt unbeeinträchtigt und online.
Bis zu dreimal schnellere Mitigation: unter 3 Sekunden
Wenn eine DDoS-Attacke beginnt, zählt jede Sekunde. Selbst ein kurzer Ausbruch von schädlichem Traffic kann zu sichtbaren Störungen führen, wenn er kritische Dienste, Anwendungspfade oder kundenorientierte Infrastruktur überlastet.
Das bisherige System erreichte bereits starke Mitigation-Zeiten von unter 10 Sekunden. Die neue Generation reduziert dieses Mitigation-Fenster auf unter 3 Sekunden. Das ist bis zu dreimal schneller als zuvor.
In der Praxis bedeutet das, dass Angriffe deutlich früher erkannt und mitigiert werden, wodurch die Wahrscheinlichkeit spürbarer Störungen für Ihre Nutzer sinkt. Das Ergebnis ist nicht nur schnellerer Schutz, sondern auch eine stärkere Servicekontinuität, wenn Verfügbarkeit am wichtigsten ist.
Mehr Transparenz: In Echtzeit sehen, was geschieht und handeln
Schutz, den Sie nicht nachvollziehen können, ist schwer zu vertrauen. Effektive DDoS-Mitigation sollte nicht wie eine Blackbox funktionieren. Sie sollte Ihrem Team Einblick geben, was geschieht, warum Maßnahmen ergriffen werden und wie Ihre Dienste geschützt werden.
Bisher wurden Angriffe zunächst mitigiert, die Dokumentation folgte anschließend in Form von Incident-Zusammenfassungen. Für viele Szenarien war das ausreichend. Doch wenn Ihr Team einen Vorfall gegenüber dem Management erläutern, Compliance-Anforderungen erfüllen oder verstehen muss, wie sich ein Angriff entwickelt hat, reichen Incident-Berichte allein nicht aus.
Die neue Link11 Network DDoS Protection gibt Ihnen Echtzeit-Einblick während eines Angriffs. Sie sehen, was blockiert wird, warum es blockiert wird und welche Dienste verfügbar bleiben. Ergänzt wird dies durch umfassende Post-Attack-Berichte, die Incident-Daten in handlungsrelevante Erkenntnisse verwandeln.
Ihr Security-Team kann schneller reagieren. Compliance-Dokumentation wird einfacher. Und das Vertrauen in Ihre Schutzinfrastruktur wächst, weil Ihr Team genau nachvollziehen kann, was geschieht, während Ihre Dienste geschützt werden.
Weniger manueller Aufwand: Schutz, der sich kontinuierlich anpasst
DDoS-Schutz kann sich nicht allein auf eine statische Konfiguration verlassen. Angriffsmuster entwickeln sich weiter, legitimer Traffic verändert sich im Laufe der Zeit, und geschäftskritische Dienste verhalten sich unter Last oft unterschiedlich. Ein Mitigation-System, das sich nicht an diese Veränderungen anpasst, kann mit der Zeit ungenauer und schwieriger zu betreiben werden.
Die bisherige Version bot durch ihre Auto-Learning-Fähigkeiten bereits eine starke Grundlage. Dennoch erforderte die Aufrechterhaltung einer effektiven Erkennung regelmäßiges manuelles Tuning, um die Schutzparameter mit dem Traffic-Profil des Kunden in Einklang zu halten.
Die nächste Generation des DDoS-Schutzes reduziert diesen operativen Aufwand erheblich. Die proaktive und für die KI-Epoche entwickelte Mitigations-Engine analysiert das Traffic-Verhalten kontinuierlich und passt die Schutzlogik mit deutlich weniger manuellem Eingreifen durch das Team des Kunden an.
Dies verringert den täglichen Betriebsaufwand und den manuellen Einstellungsaufwand, senkt das Risiko veralteter Konfigurationen während aktiver Angriffe und ermöglicht es den Sicherheitsteams, sich auf Verfügbarkeit, Ausfallsicherheit und die Reaktion auf Vorfälle zu konzentrieren, anstatt ständig die Einstellungen zur Abwehrmaßnahmen neu anzupassen.
Was bleibt gleich?
An der Art und Weise, wie Sie den Service nutzen, ändert sich nichts.
Ihr bestehendes Setup, Ihre Onboarding-Methode, Ihr Betriebsmodus und Ihre grundlegende Service-Architektur bleiben unverändert. Sie können sich weiterhin auf dieselbe globale Mitigation-Kapazität, die Deployment-Modelle Always-on, On-demand oder hybrid sowie den DSGVO-konformen Betrieb verlassen.
Das Upgrade verbessert die Schutz-Engine hinter dem Service. Es erfordert nicht, dass Sie überdenken, wie der Service bereitgestellt oder betrieben wird.
Für wen wurde diese Weiterentwicklung gebaut?
Die neue Generation von Link11 Network DDoS Protection wurde für Unternehmen entwickelt, die:
- komplexe Angriffsvektoren bewältigen müssen, die längst über reine Volumetrik hinausgehen.
- maximale Verfügbarkeit als geschäftskritische Anforderung definieren und keine einzige Sekunde Ausfallzeit tolerieren können.
- Transparenz und Nachvollziehbarkeit benötigen – für interne Teams, das Management und die Compliance.
- den operativen Aufwand reduzieren möchten, ohne Kompromisse bei der Schutzqualität einzugehen.
- Dual-Stack-Netzwerke betreiben und sowohl IPv4- als auch IPv6-Schutz benötigen.
Kurz gesagt: für alle, die ihre Infrastruktur nicht nur absichern, sondern vollständig verstehen und kontrollieren möchten.
Fazit
Angreifer entwickeln sich ständig weiter und das sollten die Tools, auf die Sie sich verlassen, ebenfalls tun. Die Netzwerk-DDoS-Schutzlösung der nächsten Generation von Link11 bietet nun volle IPv6-Unterstützung, adaptive Abwehrmaßnahmen auf Vektorebene, dreimal schnellere Reaktionszeiten, vollständige Echtzeit-Transparenz und einen deutlich geringeren Betriebsaufwand. All dies basiert auf der bewährten, datensouveränen und ausfallsicheren Infrastruktur, der Sie bereits vertrauen.
Wenn Sie sehen möchten, was das für Ihre spezifische Umgebung bedeutet, nehmen Sie Kontakt mit uns auf. Wir zeigen Ihnen, wie die neue Generation in Ihrer Infrastruktur funktioniert.
Next-Gen Network DDoS Protection Vergleich
Wenn starker DDoS-Schutz
noch besser wird
Schnellere Mitigation, IPv6-Parität, bessere Transparenz und deutlich weniger manueller Aufwand.
Alle verfügbaren Mitigationen werden gleichzeitig aktiviert, unabhängig von der Angriffsart.
Wendet gezielte Mitigation mit höherer Präzision an, unterscheidet legitimen von illegitimem Traffic und blockiert nur das Nötige.
Die Erkennung beruhte auf statischer, kundenspezifischer Konfiguration und erforderte regelmäßiges manuelles Nachjustieren.
Nutzt verhaltensbasierte Erkennung, die aus Live-Traffic-Mustern lernt, sich kontinuierlich verbessert und so False-Positives reduziert.
Eingeschränkter Einblick in einzelne Angriffs- und Mitigation-Ereignisse.
Bietet vollständige Sichtbarkeit über jedes Angriffs- und Mitigation-Ereignis durch Echtzeit-Logs, Reason-Codes und Dashboard-Reporting.
Unter 10 Sekunden.
Unter 3 Sekunden – verkürzt das Zeitfenster für Angreifer und beschleunigt den Schutz.
Unterstützte nur IPv4.
Volle Abdeckung von IPv4 und IPv6 für durchgängigen Schutz in modernen Umgebungen.
Mehr manuelles Nachjustieren und laufende Anpassungen erforderlich.
Reduziert manuelle Eingriffe durch intelligentere Automatisierung und präzisere Entscheidungen.
Das könnte Ihnen auch gefallen:





Die DDoS-Angriffe von heute sind nicht mehr nur simple Volumen- oder Protokollattacken. Sie stammen aus legitimen Netzen, ahmen echten Traffic nach und treten in Form kurzer, intensiver Peaks auf, sodass Sicherheitsteams kaum Zeit für manuelle Gegenmaßnahmen bleiben. Link11 hat seine DDoS-Abwehrlösung für Layer 3 und 4 von Grund auf neu entwickelt.
Die Next-Gen Network DDoS Protection ist bereit für die KI-Era und kombiniert proaktiven Schutz und verhaltensbasierte Erkennung mit vollständiger IPv4- und IPv6-Abdeckung für moderne Infrastrukturen. Dies stellt einen bedeutenden architektonischen Wandel bei der DDoS-Erkennung und -Abwehr dar, der durch einen höheren Automatisierungsgrad und eine geringere Abhängigkeit von manuellen Anpassungen gekennzeichnet ist.
Die Plattform ist vollständig auf europäische Datensouveränität ausgelegt – architektonisch verankert, nicht nachträglich aufgesetzt. Denn sie läuft auf der eigenen Cloud-Infrastruktur von Link11 und die Sicherheitsdaten werden in Europa gehostet. Dadurch können Unternehmen die Kontrolle über ihre Daten behalten, Rechtsunsicherheiten verringern und ihre Abhängigkeit von außereuropäischen Cloud-Anbietern begrenzen.
Verhaltensbasiert, präzise und vollständig transparent
Bisherige Lösungen stützten sich oft auf starre Regelsysteme und statische Schwellenwerte. Dieser Ansatz war zwar gegen volumetrische Angriffe wirksam, reicht aber angesichts der heutigen KI-gesteuerten, adaptiven Angriffsmuster nicht mehr aus. Deshalb hat Link11 die Architektur nicht überarbeitet, sondern sie von Grund auf neu entwickelt – basierend auf Erkenntnissen aus mehr als einer Million bisher abgewehrter DDoS-Attacken und Deep Training.
„DDoS-Angriffe werden heute zunehmend mithilfe von KI generiert, sie sind präzise und darauf ausgelegt, klassische Erkennungslogik zu überlisten. Wir sehen diese Produktversion nach über 12-monatiger Entwicklungs- und Testphase nicht als Update, sondern als Runderneuerung: eine Plattform, die mit der aktuellen Bedrohungslage Schritt hält und auch zukünftigen Anforderungen gerecht wird“, sagt Jens-Philipp Jung, CEO von Link11. „Jeder, der eine Infrastruktur schützt, braucht eine Lösung, die selbstständig mitdenkt, statt einer, die nachjustiert werden muss.”
Mit der Next-Gen Network DDoS Protection geht Link11 über die klassische Verhaltensanalyse hinaus. Jeder Angriffsvektor wird einzeln behandelt. Statt einer pauschalen Reaktion auf volumetrische Angriffe, Protokollattacken oder Amplification-Vektoren werden gezielte Gegenmaßnahmen initiiert. Das senkt die Anzahl der Fehlalarme deutlich und beschleunigt die vorher schon bahnbrechende Mitigation von unter 10 Sekunden für unbekannte Vektoren auf jetzt unter drei Sekunden. Dies ist eine der zahlreichen Verbesserungen zur bisherigen Network DDoS Protection von Link11. Bekannte Vektoren werden wie bisher in nahezu Echtzeit mitigiert.
Darüber hinaus sehen Sicherheitsteams während eines Angriffs direkt, was blockiert wird und warum, und welche Services währenddessen verfügbar bleiben. Unternehmen können somit ihre Verfügbarkeit, Kundenzugänge sowie Umsatz- und Geschäftskontinuität sicherstellen.
Robuster Schutz für moderne Infrastrukturen
Die neue Lösung ist dank modernster Technologie von Beginn an konsequent auf Anwenderfreundlichkeit ausgerichtet. Mittels Echtzeit-Protokollen, Reason Codes und einem neuen Dashboard erhalten Sicherheitsteams detaillierte Einblicke in den Verlauf von Angriffen sowie in die angewendeten Abwehrmaßnahmen. Sie sehen auch, warum bestimmter Datenverkehr blockiert oder zugelassen wird. „Bei der Entwicklung dieser neuen Lösung hat uns ein Gedanke geleitet: Resilienz ist keine technische Kennzahl, sondern ein geschäftliches Versprechen. Next-Gen Network DDoS Protection wurde entwickelt, um Anwendern dabei zu helfen, dieses Versprechen einzuhalten“, erklärt Marc Lamik, CPO von Link11.
Da die Plattform kontinuierlich aus Live-Traffic-Mustern lernt und ihre Erkennungslogik laufend selbst anpasst, wird der Bedarf an manueller Feinabstimmung erheblich reduziert. SOC-Teams müssen seltener eingreifen, da das System präzisere Entscheidungen trifft. Die Network DDoS Protection bietet vollständige Parität zwischen IPv4 und IPv6. Dies ist ein entscheidender Faktor in modernen Infrastrukturen, in denen Dual-Stack längst zum Standard geworden ist.
Für bestehende Kunden bedeutet der Versionswechsel keinen Konfigurationsaufwand. Die Migration ist ein interner Routing-Wechsel ohne Downtime. Baselines und Konfigurationen bleiben erhalten, der Wechsel erfolgt ohne Unterbrechung des Schutzes.
Next-Gen Network DDoS Protection ist ab sofort verfügbar – für bestehende Kunden ebenso wie für Unternehmen, die neu auf Link11 setzen.
Ein zweistufiger DDoS-Angriff mit einer Bandbreite von über einem Terabit und gezielten Zugriffsversuchen auf die Bereiche Login, Download und Admin zeigt: Moderne Angreifer testen die Systeme nicht vor, sondern auch während eines Angriffs.
Es gab zwei Angriffswellen mit einer zehnstündigen Pause dazwischen. Insgesamt wurden über 335 Millionen Requests gesendet. Darunter gezielte Versuche um sich in Login-Bereiche einzuloggen, Dateien herunterzuladen und WordPress-Admin-Zugänge zu finden. Was auf den ersten Blick wie eine klassische volumetrische DDoS-Attacke aussieht, entpuppt sich bei näherer Analyse als hybride Attacke: Lärm als Ablenkung, Infiltrationsversuche als eigentliches Ziel.
Erste Welle: Über einem Terabit und trotzdem kaum Schäden
Der erste Spike war massiv. Es gab mehr als ein Terabit Bandbreite, rund 25.000 Requests pro Sekunde und knapp 60 Millionen parallele Sessions im Spitzenwert. Die Quell-IPs ließen sich überwiegend großen Cloud-Anbietern und Hosting-Providern zuordnen. Es handelte sich also nicht um ein diffuses IoT-Botnetz, sondern um konzentrierte Serverkapazität. Die Web Application Firewall blockte allerdings den überwältigenden Großteil der Requests: Weniger als 58.000 Requests erreichten den Origin-Server.
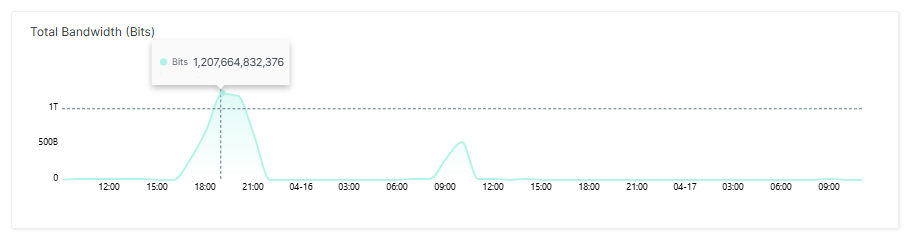
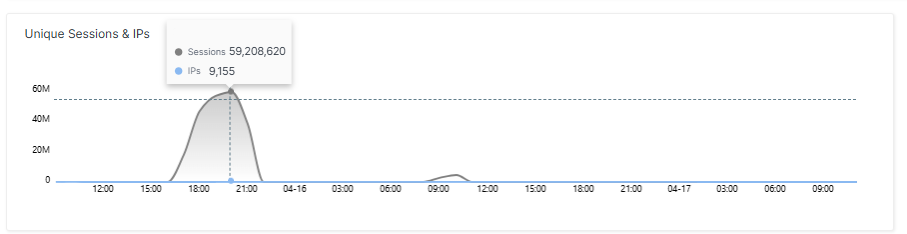
Technisch war der Angriff kein Meisterwerk. Es handelte sich um einen Layer-7-HTTP-Flood mit synthetisch rotierenden User-Agents. Die entscheidende Frage ist jedoch eine andere: Warum haben 10.000 unterschiedliche IP-Adressen zusammen fast 60 Millionen Sessions erzeugt? Weil es sich bei den dahinterliegenden Maschinen um ressourcenstarke Geräte wie Server handelte – nicht um Heimrouter oder Kameras. Solche Cloud-Instanzen können Hundertausende parallele Verbindungen aufbauen. Ein IoT-Gerät schafft das nicht. Am Ende ist es eine Frage der Rechenleistung.
Erfahren Sie mehr über eine einfach zu implementierende und äußerst effektive WAAP-Lösung.
Alles aus einer Hand und auf Wunsch als vollständig verwalteter Service.
Kein reiner DDoS – gezielte Zugriffsversuche auf sensible Bereiche
Was diesen Angriff von einem gewöhnlichen Überlastungsangriff unterscheidet, zeigt sich in der URL-Verteilung der Requests. Die Angreifer haben nicht blind den Root-Pfad bombardiert. Stattdessen haben sie gezielt Download-Seiten zugegriffen, Login-Formulare mit Anfragen geflutet und versucht, den WordPress-Admin-Bereich zu erreichen. Content-Filter haben keine SQL-Injection– oder XSS-Muster registriert. Offenbar wollten die Angreifer keine Sicherheitslücken ausnutzen, sondern durch eine hohe Anzahl von Anfragen Zugänge erzwingen: Brute-Force unter dem Deckmantel eines DDoS-Angriffs.
Angegriffene Bereiche:
- Root-Domain (Hauptlast)
- Download-/Content-Seiten
- Login-Formular
- WordPress-Admin-Pfad
Technische Signatur des Angriffs:
- Layer-7-HTTP-Flood
- Synthetische User-Agents
- Keine SQLi oder XSS-Verusche
- Brute-Force-Muster auf Login-Bereich
Eine Besonderheit, die wir gesehen haben: aus über 300.000 Requests konnte sich genau ein einziger Request an der WAF vorbeischmuggeln. Das ist kein Fehler in der Konfiguration, sondern ein statistischer Effekt, der auftritt, wenn Tausende legitim wirkende Cloud-IPs jeweils wenige Anfragen senden. Eine davon rutscht durch, bevor die Rate-Limiting-Regel greift. Das klingt nach einer Kleinigkeit. In der Praxis bedeutet es jedoch: Angreifer mit genügend verteilten Ressourcen können Mitigation-Systeme auch ohne direkten Bypass-Exploit systematisch aushöhlen.
Zweite Welle: kleiner, aber mit gestiegener Latenz
Zehn Stunden nach dem ersten Spike folgte ein zweiter Angriff mit einem Volumen von rund 500 Gbit/s. Er war kleiner als der erste, hatte aber eine interessante Wirkung. Die Latenz war beim zweiten Spike höher als beim ersten, obwohl der Angriff schwächer war. Der Grund: Die Requests pro Sekunde konzentrierten sich beim zweiten Spike auf das eigene System, die CPU-Auslastung stieg schneller und die automatische Skalierung hatte weniger Zeit zum Reagieren.
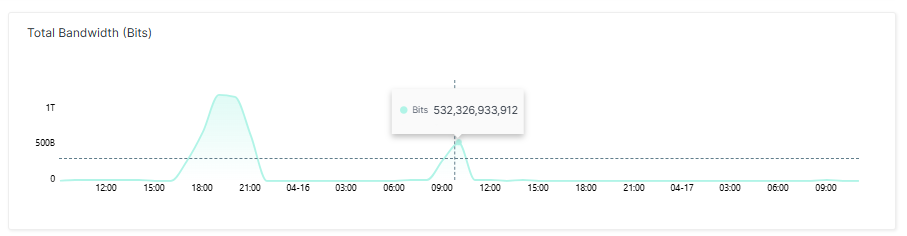
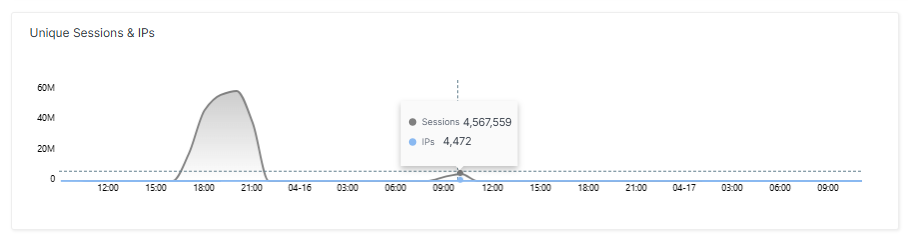
Dies verdeutlicht eine oft unterschätzte Wahrheit über DDoS-Mitigation: Bandbreite ist nicht der einzige Stressfaktor. Anfragen pro Sekunde belasten die CPU unabhängig von der übertragenen Datenmenge. Wer nur auf Bandbreiten-Schwellwerte schaut, übersieht, wann ein System tatsächlich in die Knie geht.
Der zweite Angriff war halb so groß, aber intensiver in Bezug auf die Latenz. Warum? Weil nicht die Bandbreite, sondern die Anzahl der Requests pro Sekunde die CPU-Last bestimmt. Ein kleinerer Angriff kann somit mehr spürbaren Schaden anrichten als ein größerer, wenn er die richtigen Engpässe trifft.
Cloud-Missbrauch: Ein strukturelles Problem
Die Herkunft des Traffics wirft eine unbequeme Frage auf. Nahezu alle größeren IP-Blöcke, die für Angriffe genutzt wurden, gehören zu bekannten Cloud- und Hosting-Anbietern. Diese IPs stehen in vielen Systemen auf Whitelists, was nicht auf Nachlässigkeit zurückzuführen ist, sondern darauf, dass legitime Dienste regelmäßig über genau diese Adressen kommunizieren. Wer einen Traffic-Filter baut, der zum Beispiel Microsoft-IPs grundsätzlich blockiert, schließt damit auch einen Großteil des normalen Traffics aus.
Genau das ist das strukturelle Problem: Cloud-Infrastruktur ist günstig, anonym buchbar und technisch vertrauenswürdig. Die Frage, ob diese Ressourcen gekauft, gemietet oder kompromittiert wurden, ist aus Verteidigerperspektive fast zweitrangig. Tatsache ist, dass Angriffe in diesem Umfang – über ein Terabit, hunderte Millionen Requests – mittlerweile monatlich auftreten. Vor zwei Jahren waren solche Angriffe deutlich seltener.
Verhaltensbasierte Erkennung schlägt IP-Reputation. Wer nur auf bekannte „Bad Actors” wartet, läuft der Realität hinterher. Entscheidend ist, anomales Verhalten auf Applikationsebene frühzeitig zu identifizieren. Unabhängig davon, aus welchem Rechenzentrum der Traffic stammt.
Sie haben Fragen, wie Sie sich effektiv gegen Cyberangriffe schützen können? Unsere Sicherheitsexperten stehen Ihnen jederzeit rund um die Uhr zur Verfügung.
Jetzt kontaktieren >>
Das könnte Ihnen auch gefallen:


Link11 hat Kenntnis von einem Sicherheitsvorfall bei dem Market-Intelligence-Anbieter Klue erhalten, der nach aktuellem Stand zahlreiche Klue-Kunden betrifft. Klue ist über OAuth-basierte API-Integrationen mit Salesforce-CRM-Umgebungen seiner Kunden verbunden; auch Link11 nutzte eine solche Integration.
Nach aktuellem Stand missbrauchten Angreifer ein nicht mehr aktiv genutztes, aber weiterhin gültiges Klue-Integrationskonto, beziehungsweise zugehörige OAuth-Tokens, um über bestehende Integrationsberechtigungen bestimmte CRM-Daten aus angebundenen Salesforce-CRM-Umgebungen abzufragen. Bei Link11 betraf dies bestimmte geschäftliche Kontakt- und vertriebsbezogene CRM-Daten.
Weder die Kernsysteme noch die Produkte, die operative Sicherheitsinfrastruktur oder die Kundensysteme von Link11 waren von dem Vorfall betroffen.
Was ist passiert?
Klue war über OAuth-basierte API-Integrationen mit Salesforce-CRM-Umgebungen mehrerer Kunden verbunden; auch Link11 nutzte eine solche Integration. Angreifer missbrauchten gültige Integrationsberechtigungen im Zusammenhang mit Klue, um über bestehende Berechtigungen bestimmte CRM-Daten abzufragen. Bei Link11 betraf dies bestimmte geschäftliche Kontakt- und vertriebsbezogene Daten in unserer Salesforce-CRM-Umgebung.
Welche Daten sind betroffen?
Nach den bisherigen Erkenntnissen beschränkte sich der Zugriff auf bestimmte Daten in der Salesforce-CRM-Umgebung von Link11. Dazu gehören insbesondere geschäftliche Kontaktdaten wie Namen, geschäftliche E-Mail-Adressen und Telefonnummern sowie Unternehmens-, Account- und vertriebsbezogene CRM-Informationen.
Nach aktuellem Stand sind keine besonderen Kategorien personenbezogener Daten im Sinne von Art. 9 DSGVO betroffen.
Was haben wir unternommen?
Nach Bekanntwerden des Vorfalls haben wir eine funktionsübergreifende Taskforce aus IT, Security, Legal und Datenschutz eingerichtet, um die technische Analyse, Eindämmungsmaßnahmen, Datenschutzbewertung und Kommunikation zu koordinieren. Die betroffene Klue-/Salesforce-Integration wurde deaktiviert und entfernt; alle der Integration zugeordneten OAuth-/API-Tokens in unserer Umgebung wurden widerrufen.
Den Vorfall haben wir innerhalb der vorgeschriebenen Frist der zuständigen Datenschutzbehörde gemeldet. Parallel überprüfen wir unsere Drittanbieter-Integrationen mit Blick auf Berechtigungen, Token-Lebenszyklen, Monitoring und Governance und setzen zusätzliche technische und organisatorische Kontrollen um.
„Der Vorfall zeigt, wie wichtig eine konsequente Kontrolle von SaaS- und Drittanbieter-Integrationen ist. Es gibt keine Anzeichen dafür, dass die Kernsysteme von Link11, unsere Produkte, operative Sicherheitsinfrastruktur oder Kundensysteme vom Vorfall betroffen waren. „Wir überprüfen unsere Drittanbieter-Kontrollen fortlaufend und stärken sie dort, wo zusätzliche Maßnahmen erforderlich sind“, sagt Jens-Philipp Jung, CEO von Link11.
Was bedeutet das?
Technische Maßnahmen an Link11-Produkten oder Kundensystemen sind nach aktuellem Stand nicht erforderlich. Betroffene Personen und Geschäftskontakte sollten jedoch aufmerksam gegenüber unerwarteten E-Mails, Anrufen oder Nachrichten sein, die sich auf Link11, Klue, Salesforce oder diesen Vorfall beziehen.
Bitte öffnen Sie keine verdächtigen Links oder Anhänge und geben Sie keine Zugangsdaten weiter. Wenn Sie Zweifel an der Echtheit einer Nachricht haben, kontaktieren Sie uns bitte direkt unter compliance@link11.com.
Link11, europäischer Anbieter für Cloud-basierte IT-Sicherheitslösungen im Bereich Network Security und Web Application Security verstärkt sein Engagement für digitale Souveränität und eröffnet einen „Technical Customer Excellence Hub” in Lissabon. Damit verlagert das Unternehmen seinen technischen Kundenservice in die Europäische Union.
„Mit dem Hub in Lissabon beantworten wir die konkreten regulatorischen Anforderungen, die für den europäischen Markt deutlich gestiegen sind“, erklärt Jens-Philipp Jung, CEO von Link11. Ab dem 4. Quartal 2026 wird der überwiegende Teil des technischen Supports aus Lissabon erbracht – mit maximaler Compliance-Sicherheit für regulierte Branchen.
Antwort auf DORA, NIS2 und KRITIS
Mit dem neuen Standort reagiert Link11 auf die gestiegenen Anforderungen an Resilienz und Datensouveränität, wie sie in Regelwerken wie DORA, NIS2 und dem KRITIS-Dachgesetz festgelegt sind. „Für uns steht damit eine nachvollziehbare und verlässliche Positionierung zu den Erwartungen regulierter Kunden im Fokus“, so Jung weiter.
Gleichzeitig betont das Unternehmen seine strategische Ausrichtung als europäischer Anbieter. „Wir setzen voll auf europäische Datensouveränität und stärken damit nicht nur die Resilienz unserer Kunden, sondern auch die gesamte Wirtschaftsregion“, hebt Marc Lamik, Chief Product Officer bei Link11 hervor. Das EU-Support Center ist mehr als nur ein zusätzlicher Standort: Er markiert die Weiterentwicklung des Kundenservice zu einem Excellence-Team, das rund um die Uhr komplexe Vorfälle löst.
Europäisches Engagement: Mehr als ein Standort
Der Lissabon-Hub ist somit ein zentraler Bestandteil der Link11-Strategie, um Kundenservice und technische Expertise in Europa zu bündeln. Marc Lamik, der bereits mehrere Firmen in Portugal aufgebaut hat, treibt als Geschäftsführer den Aufbau des Standorts und die Rekrutierung des Teams voran. „Lissabon ist der ideale Standort, um unser europäisches Engagement zu stärken. Hier finden wir nicht nur technische Top-Talente, sondern können auch unsere Botschaft unterstreichen: Service aus Europa für Europa“, erläutert Lamik.
Eigene Security Engineers statt Drittanbieter
Anstatt auf Drittanbieter zu setzen, investiert das Unternehmen in eigene Security Engineers, die die KI-gestützten Lösungen von Link11 von Grund auf verstehen. „Wir bauen ein Top-Notch-Team auf, das unsere Technologie lebt und unsere Kunden optimal unterstützt“, so Lamik weiter. Lissabon bietet dabei nicht nur Zugang zu einem exzellenten Talentpool, sondern auch mehrsprachige Kompetenz (Deutsch, Englisch, Portugiesisch), was für den europäischen Markt von entscheidendem Vorteil ist.
Noch mehr Sicherheit ab dem 4. Quartal 2026
Für Kunden aus KRITIS-Bereichen, Finanzinstituten und sicherheitssensiblen Unternehmen bedeutet der neue Hub eine zusätzliche Absicherung: Ab dem 4. Quartal 2026 wird der Support ausschließlich aus der EU heraus erbracht. Dabei gilt der volle EU-Rechtsrahmen, es gibt kein Drittstaatenrisiko und keine aufwendigen Prüfverfahren.
In unserem aktuellen Cyber-Insight schauen wir uns eine politisch motivierte DDoS-Attacke auf ein Rüstungsunternehmen an. Es war ein Layer-7-Angriff, kein klassischer volumetrischer Flood auf Netzwerkebene, sondern gezielter Druck auf die Applikationsschicht. Jeder Request muss von der WAF bewertet werden – Rate Limiting, Session-Tracking, Fingerprinting. Das kostet Rechenzeit auf der Verteidigungsseite, nicht nur Bandbreite.
73 IPs, drei Millionen Sessions – das ist kein IoT-Botnetz
Klassische volumetrische DDoS-Angriffe setzen auf eine breite Streuung: Tausende kompromittierter Endgeräte – Router, Kameras, NAS-Systeme – senden gleichzeitig Anfragen. Hier war es anders. Die Angriffslast wurde auf eine kleine Zahl von IP-Adressen verteilt, von denen einzelne mit einer enormen Sessionrate arbeiteten. Eine einzige IP-Adresse hat 17 Millionen Requests geliefert. Nur 73 IP-Adressen haben gemeinsam über drei Millionen parallele Sessions geöffnet.
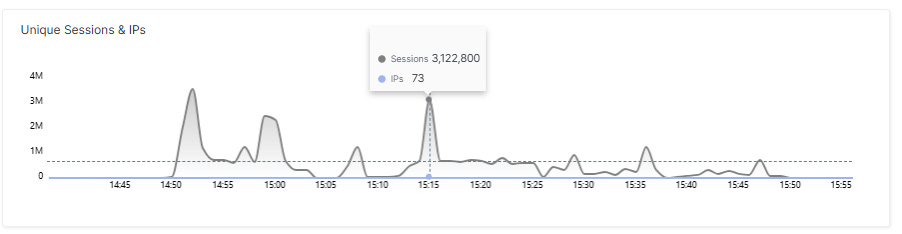
Ein IoT-Gerät hat einfach nicht die nötige CPU-Leistung für solche Lasten. Hier sieht es nach gemieteten Cloud-Ressourcen aus: hohe Rechenleistung, wenige IPs, maximale Request-Rate pro Knoten.
Die ASN-Analyse der angreifenden IP-Adressen hat bestätigt, was wir schon vermutet haben: Ein Großteil des Traffics – über 50 Millionen Requests – lassen sich Cloud-Infrastrukturen zuordnen. Darunter sind bekannte Hyperscaler und große CDN-Anbieter. Das kann bedeuten, dass der Angreifer entweder Cloud-Instanzen kompromittiert oder diese direkt gebucht hat. Vielleicht über anonyme Zahlungswege oder gestohlene Accounts.
Das führt auch zur Frage: Wer hat Zugang zu diesen Ressourcen und wie?
Geopolitischer Kontext: Wer ist dazu in der Lage – und warum?
Der Angriff fand während des aktiven Konflikts zwischen Israel und dem Iran statt. Diese Kombination legt eine politisch motivierte Urheberschaft nahe, auch wenn eine direkte Zuordnung nicht möglich ist.
Was die Analyse jedoch erschwert, ist die Tatsache, dass der iranische Staat während des Konflikts den Internetzugang stark eingeschränkt hat. Das bedeutet: Entweder handelt es sich um außerhalb Irans operierende, staatlich affiliierte Akteure oder um Proxy-Gruppen, die im Auftrag handeln und über entsprechende Infrastrukturzugänge verfügen. Beides setzt eine gewisse organisatorische Reife voraus.
Cloud-Kapazität ist günstig, anonym buchbar und technisch schlagkräftig. Ein vergleichbares IoT-Botnetz aufzubauen, wäre um ein Vielfaches aufwändiger und deutlich leichter zu blockieren. Daher sind verschiedene Szenarien denkbar.
Erfahren Sie mehr über eine einfach zu implementierende und äußerst effektive WAAP-Lösung.
Alles aus einer Hand und auf Wunsch als vollständig verwalteter Service.
Angriffstechnik: Simpel, aber skaliert
Auf den ersten Blick wirkten die User-Agents der angreifenden Clients divers: verschiedene Browser-Strings, unterschiedliche Versionen. Bei näherer Analyse zeigte sich jedoch ein eindeutiges Muster. Es handelte sich um algorithmisch generierte Strings, bei denen lediglich die Versionsnummer des Browser-Identifiers inkrementiert wurde. Es handelt sich also nicht um ein echtes Botnet-Diversity-Profil, sondern um ein einfaches Skript. Das reicht aus, um oberflächliche User-Agent-Filter zu umgehen, hält aber einer tieferen Verhaltensanalyse nicht stand.
Interessant war auch die Dynamik des Angriffsverlaufs. Nach dem initialen Peak mit rund neun Millionen Requests pro Minute flachte das Volumen schrittweise ab. Dabei variierte die Zahl aktiver IP-Adressen und offener Sessions stark, teilweise zwischen über 1.300 und unter 50 innerhalb kurzer Zeitfenster. Dies deutet auf ein aktives Ressourcen-Management des Angreifers hin. Botnet-Nodes wurden zu- und abgeschaltet, möglicherweise, um die Kosten zu steuern oder die Angriffssignatur zu variieren.
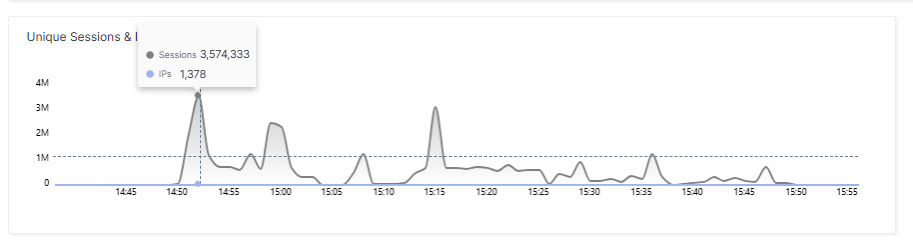
Nachdem nach einer Stunde klar war, dass die Zielinfrastruktur standhielt, reduzierte der Angreifer schrittweise die Ressourcen und stellte den Angriff schließlich ein. DDoS ist heute eben auch auf Angreiferseite eine Kosten-Nutzen-Rechnung.
Was bedeutet das für Verteidiger?
Die Attacke veranschaulicht eine strukturelle Verschiebung in der Bedrohungslandschaft. Cloud-Ressourcen demokratisieren nicht nur Innovation, sondern auch Angriffsfähigkeiten. Wer heute über das nötige Budget und Grundwissen verfügt, kann einen Angriff dieser Größenordnung ohne eigene Hardware initiieren.
Fest steht: Ein Angreifer, der über 50 Millionen Requests aus westlichen Cloud-Segmenten orchestrieren kann, verfügt über operative Reife. Die Abwehr solcher Angriffe erfordert mehr als einfaches Rate Limiting. Benötigt werden verhaltensbasierte Analyse, ASN-Reputationsdaten und die Fähigkeit, Sessions auf Layer-7-Ebene zu korrelieren, statt nur einzelne IP-Adressen zu sperren.

Wer DDoS-Schutz nur auf Netzwerkebene denkt, ist auf Angriffe dieser Art nicht vorbereitet. Die Bedrohung hat sich von der Bandbreite zur Applikationslogik und von IoT-Botnetzen zu Cloud-nativen Angriffsinfrastrukturen verlagert. Und die nächste Attacke dieser Klasse kommt nicht aus einem Keller. Sie kommt aus einer „Availability Zone“ in Frankfurt, London oder New York.
Ist Ihre Applikationsebene auf Cyberangriffe dieser Größenordnung vorbereitet? Schauen Sie sich gemeinsam mit einem unserer Experten Ihre kritischen Webservices und Assets an. Kontaktieren Sie uns jederzeit für ein tiefergehendes Gespräch.
Das könnte Ihnen auch gefallen:
Wenn Ihr Netzwerk online ist und Umsatz generiert, ist es ein potenzielles Ziel. Das ist keine Übertreibung, sondern die Realität des modernen Internets. Und wenn Sie aktuell auf einen Standard-Transitanbieter mit einem aufgesetzten DDoS-Schutz setzen, besteht die Möglichkeit, dass Ihr Verteidigung eine Lücke hat, die Sie bisher noch nicht erkannt haben.
Dieser Artikel erklärt, was Link11 Clean Transit ist, wie es funktioniert, für wen es entwickelt wurde und warum die Art und Weise, wie die meisten Netzwerke heute geschützt werden, sie anfälliger macht als ihre Betreiber erkennen.
Das Problem mit der heutigen Angriffslage
Die meisten Netzwerke sind nach demselben Prinzip aufgebaut: IP-Transit wird bei einem Carrier eingekauft, der Konnektivität zum Internet bereitstellt. Separat dazu wird entweder ein DDoS-Mitigation-Dienst hinzugekauft oder man verlässt sich auf den eingeschränkten Schutz, den der Transitanbieter mitliefert. Wenn ein Angriff eintrifft, wird der Traffic zu einem Scrubbing-Center umgeleitet, bereinigt und dann zurückgeleitet.
Jahrelang hat das gut genug funktioniert. Angriffe waren groß, aber die Reaktionszeit reichte aus. Das Problem ist, dass sich Angriffe grundlegend verändert haben, die traditionelle Architektur jedoch nicht.
DDoS-Attacken sind 2025 um 121 Prozent gewachsen und erreichten zum Jahresende einen Durchschnitt von 5.376 automatisch abgewehrten Angriffen pro Stunde. Der größte einzelne Angriff in diesem Jahr erreichte einen Peak von 31,4 Tbps und dauerte 35 Sekunden. Das ist kein Tippfehler. Der größte jemals öffentlich dokumentierte DDoS-Angriff war vorbei, bevor die meisten automatisierten Systeme ihre Reaktion abgeschlossen hätten. Insgesamt wurden 2025 weltweit 47,1 Millionen DDoS-Angriffe verzeichnet. Das entspricht mehr als einem Angriff pro Sekunde, jeden Tag des Jahres.
Zwei technische Entwicklungen treiben dieses Wachstum an. Erstens verfügen groß angelegte IoT-Botnets inzwischen auch Angreifer mit geringen technischen Kenntnissen über Zugang zu enormen Trafficvolumen. Das Aisuru-Kimwolf-Botnet, das für viele der größten Angriffe im Herbst 2025 verantwortlich war, bestand aus schätzungsweise einer bis vier Millionen kompromittierten Android-TV-Geräten und war in der Lage, auf Abruf hyper-volumetrische Floods zu erzeugen.
Zweitens verteilen Carpet-Bombing-Angriffe den Traffic über ganze CIDR-Blöcke statt einzelne IP-Adressen. Das hebelt per-IP-Erkennungsschwellenwerte und Rate-Limiting-Regeln aus, weil keine einzelne Adresse einen Trigger-Punkt überschreitet, auch wenn das Subnetz als Ganzes überflutet wird. Mitigation-Systeme, die auf Einzelziel-Basis arbeiten, lösen nicht aus, bis das Muster auf Präfix-Ebene erkannt wird. Zu diesem Zeitpunkt ist oft schon erheblicher Schaden entstanden.
Warum Overlay-Mitigation bei schnellen, großen Angriffen versagt
Das Kernproblem bei aufgesetzter DDoS-Mitigation ist die Reaktionskette. Wenn die Anomalieerkennung anschlägt, läuft der Standardprozess so ab: Angriffssignatur erkennen, Traffic per BGP-Announcement zu einem Scrubbing-Center umleiten, Traffic bereinigen, sauberen Traffic zurückleiten. Jeder dieser Schritte kostet Zeit. Unter realistischen Bedingungen dauert der gesamte Erkennungs- und Mitigations-Zyklus zwischen 10 und 30 Sekunden.
Wenn der größte dokumentierte Angriff bei 31,4 Tbps peaked und in 35 Sekunden vollständig abgeschlossen ist, ist ein Aktivierungsfenster von 10 bis 30 Sekunden keine Kleinigkeit. Es ist eine Lücke, die den Großteil oder die gesamte Angriffsdauer abdeckt. Das Mitigation-Layer war für diese Art von Ereignis schlicht nicht ausgelegt, und es gibt keine Konfigurationsänderung, die das Problem schließt, weil die Verzögerung der Architektur inhärent ist.
Kurzzeit-Angriffe werden auch zunehmend als bewusste Technik eingesetzt. Angreifer können Uplinks sättigen, Connection-State-Tabellen auf Stateful-Devices erschöpfen oder SLA-Verletzungen mit Floods auslösen, die unter einer Minute dauern und verschwinden, bevor eine automatisierte Reaktion Zeit hatte zu greifen. Das ist besonders schädlich für Dienste, bei denen selbst kurze Nichtverfügbarkeit direkte betriebliche Konsequenzen hat: Live-Event-Streaming, Finanzhandel, Echtzeit-Kommunikation und Online-Gaming.
Wenn Overlay-Mitigation vollständig überlastet ist, fällt der Fallback der meisten Transitanbieter auf BGP-Blackhole-Routing zurück. Eine Null-Route wird für das angegriffene Präfix propagiert, was dazu führt, dass der gesamte Traffic für diese Adressen bereits im Upstream verworfen wird. Angriffstraffic kommt nicht mehr beim Kunden an, aber legitimer Traffic auch nicht. Das Präfix verschwindet aus der Routing-Tabelle. Der Dienst des Kunden ist offline. Das schützt die eigene Infrastruktur des Carriers auf Kosten der Verfügbarkeit des Kunden.
Die finanziellen Folgen sind messbar: Laut dem ITIC 2024 Hourly Cost of Downtime Survey berichten mehr als 90 Prozent der mittelgroßen und großen Unternehmen, dass eine einzelne Stunde Ausfall über 300.000 USD kostet. Bei rund 41 Prozent dieser Unternehmen liegt die Zahl bei über einer Million USD pro Stunde. Für die größten Unternehmen in Sektoren wie Banking, Finanzdienstleistungen und Fertigung überstiegen die durchschnittlichen stündlichen Ausfallkosten laut ITIC die Marke von fünf Millionen USD.
Erfahren Sie mehr über Clean Transit von Link11.
Always-on DDoS-Abwehr direkt in Ihren Transit integriert. Kein separates Schutztool, keine Verzögerung bei der Aktivierung.
Was ist Clean Transit?
Clean Transit ist ein sicherheitsnatives IP-Transit-Produkt. Es ist kein aufgesetztes Mitigation-Layer und sitzt nicht neben dem bestehenden Transit. Es ersetzt den Upstream-Transit vollständig, mit DDoS-Scrubbing direkt in der Data Plane.
Der entscheidende architektonische Unterschied: Scrubbing ist immer aktiv. Es gibt keine Erkennungsphase, keinen Umleitungsschritt und keinen Aktivierungsverzug. Jedes eingehende Byte durchläuft die Scrubbing-Infrastruktur von Link11, bevor es an das Kundennetzwerk weitergeleitet wird. Das Filtering ist kontinuierlich und läuft mit Leitungsrate, unabhängig davon, ob gerade ein Angriff stattfindet. Sauberer Traffic ist das Einzige, was ausgeliefert wird. Das ist das Produkt.
Das eliminiert das oben beschriebene Timing-Problem vollständig. Ein 35-Sekunden-Angriff, der bei 31 Tbps peaked, wird identisch behandelt wie normaler Traffic an einem ruhigen Tag. Die Infrastruktur muss nicht erkennen, klassifizieren und reagieren, weil sie niemals aufhört zu filtern.
Es gibt auch keinen Blackhole-Fallback. Da Scrubbing dauerhaft und auf Infrastrukturebene betrieben wird, gibt es kein Szenario, in dem Link11 das Präfix eines Kunden zurückziehen müsste, um das eigene Netz zu schützen. Das Backbone ist darauf ausgelegt, Multi-Terabit-Angriffstraffic zu absorbieren, nicht ihn zu umgehen.
Wie Clean Transit technisch funktioniert
Die Integration in das bestehende Netzwerk eines Kunden erfolgt vollständig über BGP. Kunden announcen ihre IP-Präfixe gegenüber der ASN von Link11 über Standard-BGP-Sessions. Sämtlicher Traffic, der für diese Präfixe bestimmt ist, wird dann an den Ingress-Punkten abgefangen, durch die Scrubbing-Pipeline geleitet und als sauberer Traffic weitergeleitet.
Die Scrubbing-Pipeline operiert gleichzeitig über alle Peering- und Transit-Ports. Auf der Kundenseite ist kein Traffic-Steering erforderlich und es sind keine Änderungen an der internen Routing-Architektur notwendig. Der Kunde empfängt sauberen Traffic über die vereinbarte Delivery-Methode.
Return-Traffic, also ausgehend aus dem Kundennetzwerk, wird über die Interconnect-Methode zugestellt, die zur Topologie des Kunden passt. Verfügbare Optionen sind ein physischer Cross-Connect in einem Colocation-Facility, ein VLAN-Handoff an einem Internet Exchange Point wie DE-CIX, AMS-IX oder LINX, Remote Peering über Route Server oder ein GRE- bzw. IPsec-Tunnel für Kunden, die keine physische Übergabe einrichten können. Jede dieser Optionen führt die vollständige BGP-Routing-Tabelle, was Kunden optimierte Routen über die Upstream-Carrier und Peering-Partner von Link11 gibt.
Zum Produkt gehört außerdem ein Echtzeit-Monitoring-Dashboard mit Live-Traffic-Analysen, Netflow-Daten und Angriffsberichten. Das gibt Betreibern vollständige Transparenz über den eingehenden Traffic zu jedem Zeitpunkt, einschließlich während eines aktiven Angriffs, ohne dass separates Tooling oder manuelle Eingriffe zur Berichtsgenerierung notwendig sind.
Aus DSGVO- und Datensouveränitätsperspektive betreibt Link11 europäische Infrastruktur und verarbeitet Traffic innerhalb des EU-Rechtsrahmens. Für Betreiber in Deutschland, Österreich, der Schweiz oder anderswo in der EU mit Datenhaltungsanforderungen ist das sowohl für Compliance als auch für vertragliche Verpflichtungen gegenüber Kunden relevant.
Für wen Clean Transit entwickelt wurde
Clean Transit richtet sich an Netzwerkbetreiber, deren Geschäft von Verfügbarkeit abhängt und die entweder die Kosten eines Ausfalls nicht tragen können oder keine eigene Scrubbing-Infrastruktur aufbauen und betreiben wollen.
Hosting-Provider tragen typischerweise DDoS-Risiko im Auftrag ihrer Kunden. Ein Angriff auf einen Mandanten kann die gemeinsam genutzte Upstream-Kapazität beeinträchtigen und andere Kunden auf derselben Infrastruktur treffen. Clean Transit verlagert den Schutz auf die Upstream-Ebene, sodass das Scrubbing stattfindet, bevor Traffic überhaupt das Hosting-Netzwerk erreicht.
Regionale ISPs leiten Traffic für ihre Downstream-Teilnehmer. Ein erfolgreicher Angriff auf deren Upstream führt zu Konnektivitätsverlust für den gesamten Kundenstamm. Clean Transit bietet Upstream-Schutz, ohne dass der ISP eine eigene Scrubbing-Infrastruktur betreiben oder separate Mitigation-Verträge verhandeln muss.
Gaming-Plattformen gehören zu den meistangegriffenen Diensten im Internet und reagieren besonders empfindlich auf die Latenz, die durch Traffic-Umleitung entsteht. Standardmäßige Mitigation-Ansätze, die Traffic durch ein Scrubbing-Center umleiten, erhöhen die Round-Trip-Time auch dann, wenn sie korrekt funktionieren. Da Clean Transit direkt im Transit-Layer filtert, ohne Umleitung, entsteht kein zusätzlicher Latenzpfad für legitimen Traffic.
SaaS- und Cloud-Provider verkaufen Verfügbarkeit als Teil ihres Produkts. SLA-Verpflichtungen, Churn-Risiko und Reputationsschäden folgen direkt aus einem Ausfall. Diese Betreiber sehen sich häufig Angriffen auf mehrere Präfixe gleichzeitig ausgesetzt, was Carpet-Bombing-Techniken gezielt ausnutzen. Clean Transit schützt den gesamten Adressraum auf Upstream-Ebene.
Finanzdienstleister sind sowohl direkten Umsatzverlusten als auch regulatorischen Risiken durch Ausfallzeiten ausgesetzt. In manchen Jurisdiktionen sind Verfügbarkeitspflichten für bestimmte Finanzdienstleistungen regulatorisch verankert, sodass ein Ausfall nicht nur ein kommerzielles, sondern auch ein Compliance-Problem darstellt. Das 99,99-Prozent-SLA des Enterprise-Tiers ist auf diese Anforderungen ausgelegt.
E-Commerce-Betreiber werden häufig gezielt während der umsatzstärksten Zeiten angegriffen, weil der finanzielle Schaden dann am größten ist. Ein Mitigation-Service, der 20 Sekunden zum Aktivieren braucht, während ein Flash-Angriff auf einen Produkt-Launch oder ein Verkaufsevent abzielt, schützt möglicherweise nicht rechtzeitig. Always-on-Scrubbing eliminiert dieses Risiko.
Service-Tiers
Clean Transit ist in drei Tiers verfügbar. Die Preise entsprechen dem Niveau standard-mäßiger Mid-Tier-Transitanbieter. Das Argument für Clean Transit ist nicht ein niedrigerer Preis, sondern dass zum gleichen Preis Scrubbing auf Infrastrukturebene enthalten ist, statt als separater Dienst, den man verwalten und auf rechtzeitige Aktivierung hoffen muss.
Essential deckt 1 bis 10 Gbps Committed Bandwidth mit Burst auf 2x und einem 99,9-Prozent-SLA ab. Geeignet für regionale ISPs und kleinere Netzwerkbetreiber.
Professional deckt 10 bis 50 Gbps mit Burst auf 3x und einem 99,95-Prozent-SLA ab. Geeignet für Hosting-Provider und Gaming-Plattformen, bei denen Bandbreitenanforderungen höher und die Uptime direkt an Kundenverpflichtungen geknüpft ist.
Enterprise deckt 50 bis 100 Gbps und mehr mit Burst auf 5x und einem 99,99-Prozent-SLA ab. Geeignet für SaaS-Provider, Finanzdienstleister, Streaming-Plattformen und CDN-Betreiber, bei denen Ausfälle unmittelbare finanzielle und regulatorische Konsequenzen haben.
Alle Tiers beinhalten Always-on-Scrubbing, die vollständige BGP-Routing-Tabelle, alle verfügbaren Delivery-Optionen und Dashboard-Zugang. Volumenbasierte Preise sind für größere oder stufenweise Deployments verfügbar.
Was Clean Transit von herkömmlichen Lösungen unterscheidet
Am einfachsten lässt es sich so ausdrücken: Die meisten DDoS-Schutzprodukte werden aktiviert, wenn etwas schiefläuft. Clean Transit ist aktiv, bevor etwas schiefläuft, und bleibt aktiv, unabhängig davon, was passiert.
Bei einem Standard-Mitigation-Overlay hängt der Schutz davon ab, dass drei Dinge gleichzeitig funktionieren: Der Angriff wird schnell genug erkannt, die Traffic-Umleitung verursacht keine zu hohe Latenz, und die Scrubbing-Kapazität reicht für das Angriffsvolumen. Wenn auch nur eines davon nicht stimmt, versagt der Schutz. Bei Clean Transit existieren diese Variablen nicht in dieser Form. Es gibt keinen Erkennungsschritt, keine Umleitung und kein Kapazitätslimit, das nur im Angriffsfall gilt. Das Scrubbing läuft mit Leitungsrate, kontinuierlich.
Link11 hat sein Netzwerk für den Umgang mit großangelegten DDoS-Angriffen aufgebaut. Die Scrubbing-Infrastruktur, auf der Clean Transit basiert, ist dieselbe, die die Enterprise-Kunden von Link11 schützt. Clean Transit macht diese Kapazität als Wholesale-Transit-Produkt verfügbar. Kunden kaufen keine Absicherung von einem Unternehmen, das nachträglich Sicherheitsfunktionen auf ein Konnektivitätsprodukt aufgesetzt hat. Sie kaufen Konnektivität von einem Unternehmen, das das Netzwerk von Grund auf für die Absorption von Terabit-Angriffen gebaut hat.
Fazit
DDoS-Angriffe sind größer, schneller und leichter zu starten als je zuvor. Das herkömmliche Modell, Transit zu kaufen und Schutz obendrauf zu legen, wurde nicht für Angriffe in dieser Geschwindigkeit und Größenordnung entwickelt. Wenn Ihr Mitigation-Dienst einen Angriff erst erkennen muss, bevor er reagieren kann, wird es schwierig. Attacken sind heute konzipiert sind, dass sie in unter einer Minute ihre Lastspitze finden und danach teilweise genauso schnell vorbei sind, wie sie begonnen haben. Es existiert also ein Expositionsfenster, das sich durch Konfiguration allein nicht schließen lässt.
Clean Transit schließt dieses Fenster. Der Schutz ist in den Transit-Layer eingebaut. Jedes Paket wird gefiltert, bevor es Ihr Netzwerk erreicht. Kein Aktivierungsverzug, kein Blackhole-Fallback, kein separater Dienst, den man verwalten muss.
Wenn Sie Infrastruktur betreiben, bei der Ausfallzeiten Geld kosten, bei der Kunden merken, wenn Sie offline gehen, oder bei der Sie SLA- oder regulatorische Verpflichtungen einzuhalten haben, ist Clean Transit einen genaueren Blick wert. Link11 bietet eine technische Bewertung Ihres aktuellen Setups als Einstiegspunkt, ohne Verpflichtung.
Sollten Sie Fragen zur Technologie haben, stehen Ihnen unsere Cyberexperten gerne jederzeit zur Verfügung.
Jetzt kontaktieren >>
Das könnte Ihnen auch gefallen:



Nicht alle Angriffe sind spektakulär. Manche verlaufen eher unscheinbar, ohne dabei Rekordwerte bei Bandbreite oder Paketvolumen zu erreichen. So auch die folgende DDoS-Attacke: Auf den ersten Blick wirkt er eher unspektakulär, da das Volumen bei rund drei Millionen Requests lag. Im Vergleich zu groß angelegten DDoS-Kampagnen ist dies kein außergewöhnlicher Wert. Dennoch lohnt sich ein genauerer Blick auf die Struktur. Denn diese zeigt, wie Angreifer selbst mit begrenzten Mitteln versuchen, Webanwendungen gezielt zu stören.
Auffälliges Traffic-Muster: langsamer Anstieg, plötzlicher Peak
Der Traffic-Verlauf zeigte zunächst einen langsamen, kontinuierlichen Anstieg der Anfragen. Danach folgte ein einzelner, deutlich sichtbarer Peak. Im Gegensatz zu massiven volumetrischen Angriffen blieb das Gesamtvolumen jedoch moderat.

Charakteristisch war zudem, dass sich der Angriff ausschließlich auf die Root-Domain, also die Startseite der Website, konzentrierte und nicht auf spezifische Unterverzeichnisse oder API-Endpunkte. Solche Muster sind typisch für vereinfachte Botnet-Aktivitäten, bei denen keine gezielte Analyse von Anwendungspunkten erfolgt, sondern generische Anfragen an den Hauptendpunkt gesendet werden.
Geografische Einschränkung als Schutzmaßnahme
In diesem Fall war die bestehende Zugriffsbeschränkung ein wesentlicher Faktor: Für die betroffenen Domains war eine Regel aktiv, die nur Traffic aus bestimmten Regionen zuließ, wie etwa den USA und Europa. Anfragen aus anderen Ländern wurden automatisch blockiert. Ein großer Teil des Angriffsverkehrs stammte jedoch aus Ländern, die nicht auf der Whitelist standen, darunter China, Indien oder die Türkei. Diese Requests wurden unmittelbar verworfen.
Gleichzeitig wurde ein Teil des Traffics aus zugelassenen Ländern wie Deutschland blockiert. Die Ursache lag dabei nicht in der Geofilterung, sondern in anderen Schutzmechanismen wie dem Rate-Limiting.

Rate Limiting: Schutz vor zu vielen Anfragen
Rate-Limiting ist eine gängige Methode, um Webanwendungen abzusichern. Dabei wird festgelegt, wie viele Anfragen ein Client innerhalb eines bestimmten Zeitfensters stellen darf. Wird diese Schwelle von einer IP-Adresse überschritten, werden weitere Requests temporär blockiert.
Im vorliegenden Fall zeigte sich, dass ein Großteil der zugelassenen deutschen Anfragen aus genau diesem Grund abgewiesen wurde. Dies deutet darauf hin, dass die betreffenden IP-Adressen in kurzer Zeit ungewöhnlich viele Requests generierten. Ein typisches Muster für automatisierte Botanfragen.
GET-Request im Fokus
Zudem wurden auch HTTP-Anfragen mit der Methode GET blockiert. Das wirft zunächst Fragen auf, da GET die am häufigsten genutzte HTTP-Methode ist.
Um dies einzuordnen, lohnt sich ein kurzer Blick auf die Grundlagen des HTTP-Protokolls.
HTTP (Hypertext Transfer Protocol) definiert verschiedene Methoden, mit denen Clients (z. B. Browser) mit einem Webserver kommunizieren. Zu den wichtigsten zählen:
- GET: Ruft Informationen vom Server ab
- POST: Sendet Daten an den Server (z. B. Formulareingaben).
- PUT: Aktualisiert bestehende Ressourcen.
- DELETE: Löscht Ressourcen.
- HEAD: Fordert nur Header-Informationen an.
Die GET-Methode dient ausschließlich dazu, Informationen vom Server zu erhalten. Ein klassischer Seitenaufruf im Browser ist technisch gesehen ein GET-Request. Dabei werden keine Daten verändert oder gespeichert, sondern lediglich eine Ressource abgefragt.
Genau deshalb gilt GET grundsätzlich als „harmlos“: Über einen reinen GET-Request lassen sich keine Daten auf dem Server verändern oder direkt einschleusen. Injection-Angriffe zielen typischerweise auf Parameter oder andere Schwachstellen ab, nicht auf die Methode selbst.
Warum GET dennoch blockiert wird
Es kann sinnvoll sein, GET-Anfragen gezielt zu blockieren, wenn eine Anwendung diese nicht benötigt. In spezialisierten APIs oder Backend-Systemen, die ausschließlich POST-Anfragen erwarten, kann das Blockieren aller GET-Anfragen die Angriffsfläche reduzieren. Hier war ein solcher Filter aktiv. Alle GET-Anfragen wurden automatisch verworfen.
Da der beobachtete Angriff ausschließlich mit der GET-Methode arbeitete und nur die Root-Domain ansprach, wurde der Verkehr vollständig abgefangen. Es handelte sich also um eine einfache, massenhafte Nutzung der Standardmethode, um Serverressourcen zu binden.
Erfahren Sie mehr über eine einfach zu implementierende und äußerst effektive WAAP-Lösung.
Alles aus einer Hand und auf Wunsch als vollständig verwalteter Service.
Kleine Botnetze, reale Auswirkungen
Im Gegensatz zu großen Botnetzen handelte es sich um ein kleines Netz mit einer geringen Anzahl beteiligter IP-Adressen. Das bedeutet jedoch nicht, dass kein Risiko besteht.
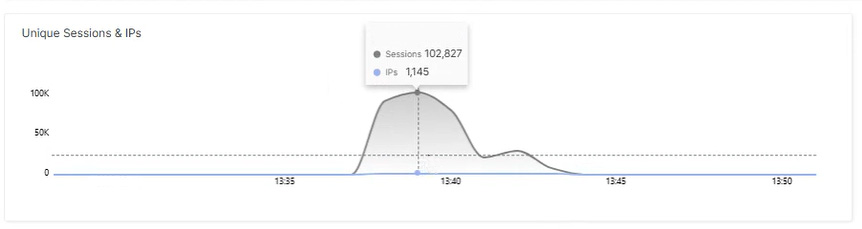
Ob ein Angriff erfolgreich ist, hängt auch von der Zielinfrastruktur ab. Eine ressourcenintensive Webanwendung oder ein schlecht skalierter Server kann bereits durch moderate Request-Zahlen überlastet werden.
Besonders bei vielen gleichzeitigen Verbindungen oder der Generierung dynamischer Inhalte steigt die CPU- und Speicherbelastung schnell an. Solche Angriffe zielen auf Anwendungsebene. Sie versuchen, Serverressourcen durch viele HTTP-Anfragen zu binden.
GET-Anfragen sind alltäglich, weshalb sie nicht pauschal als bösartig klassifiziert werden können. Erst in Kombination mit Frequenz, Herkunft und Verhaltensmustern entsteht ein belastbares Bild. Der Vorfall verdeutlicht, dass nicht die Größe des Botnetzes, sondern die Wechselwirkung zwischen Angriffsstrategie und Zielarchitektur über das Risiko entscheidet.
Ein kleiner, sauber strukturierter Angriff kann dennoch Wirkung entfalten, insbesondere bei fehlenden Schutzmechanismen. In diesem Fall blieben sie wirksam.
Haben Sie Fragen zum Thema oder brauchen Informationen, wie Sie sich ideal auf solche Angriffe vorbereiten können?
Jetzt unsere Cyberexperten kontaktieren>>
Das könnte Ihnen auch gefallen:
Wenn ein Unternehmen Ziel eines Distributed Denial-of-Service (DDoS)-Angriffs wird, ist der erste Reflex oft, den vermeintlich schädlichen Traffic so schnell und rigoros wie möglich zu blockieren. Doch was passiert, wenn die Abwehrmaßnahmen über das Ziel hinausschießen und genau die Menschen aussperren, die man eigentlich bedienen möchte?
Wenn der Schutz zum Hindernis wird: False Positives in der DDoS-Abwehr
In der Cybersicherheit beschreibt ein „False Positive“ eine Situation, in der ein Schutzsystem völlig legitimen, harmlosen Datenverkehr irrtümlich als Bedrohung einstuft und abweist. Bei der DDoS-Mitigation kann dies geschehen, wenn ein Netzwerk plötzliche, aber echte Traffic-Spitzen verzeichnet, die zum Beispiel durch eine erfolgreiche Marketingkampagne, einen großen Produkt-Launch oder saisonale Events ausgelöst werden. Ein starr konfiguriertes Abwehrsystem registriert den rapiden Anstieg der Zugriffe, verwechselt den Ansturm der echten Kunden mit einer böswilligen Bot-Attacke und blockiert sie.
Das paradoxe Ergebnis: Die IT-Infrastruktur ist zwar geschützt, aber für einen Teil der eigentlichen Zielgruppe ist der Dienst aber dennoch offline. False Positives verursachen somit direkte Serviceunterbrechungen, frustrieren Kunden und können zu Umsatzeinbußen sowie Reputationsschäden führen.
Das False-Positive-Dilemma herkömmlicher Schutzsysteme
Viele klassische DDoS-Schutzsysteme verwenden noch immer ältere Methoden wie feste Regeln oder simples Rate-Limiting. Bei schnell ablaufenden Angriffen auf Layer 3 und Layer 4 oder plötzlichen Traffic-Spitzen stoßen diese starren Methoden jedoch schnell an ihre Grenzen.
Dieses Dilemma belastet nicht nur die Endnutzer, sondern auch die internen IT- und Sicherheitsteams enorm. Für Teams im Security Operations Center und Network Operations Center bedeutet lösen bereits Störungen bei einzelnen Nutzern zeitaufwendige Ursachenanalysen aus. Die Teams verbringen Stunden damit herauszufinden, ob Ausfälle durch Angriffe oder durch Fehlalarme verursacht wurden.
Erschwert wird diese Situation zusätzlich durch traditionelle „Black-Box“-Systeme, die Traffic filtern, ohne den Administratoren transparent und nachvollziehbar zu erklären, warum eine bestimmte Verbindung überhaupt blockiert wurde.
Erfahren Sie mehr über eine einfach zu implementierende und äußerst effektive WAAP-Lösung.
Alles aus einer Hand und auf Wunsch als vollständig verwalteter Service.
Der Weg in die Zukunft: Intelligente, verhaltensbasierte Mitigation
Um diesem branchenweiten Problem zu begegnen, sollte sich der Fokus der modernen Cybersicherheit zunehmend auf intelligente, verhaltensbasierte Analysen (Behavioral Analytics), gepaart mit adaptiven Engines, verlagern. Statt pauschal Datenverkehr zu drosseln, analysieren solche Systeme Live-Traffic-Muster mithilfe einer hochentwickelten verhaltensbasierten Erkennung und setzen auf eine granulare Per-Protokoll- und Per-Port-Filterung. Das bringt drei entscheidende Vorteile für moderne Netzwerkinfrastrukturen:
- Geringerer Bedarf für Manual Tuning durch adaptives Lernen: Eine Auto-Learning Mitigation Engine passt sich in Echtzeit an das normale Verhalten des Netzwerks an. Dadurch werden False Positives, die unnötige Ausfallzeiten verursachen, drastisch reduziert. Das aufwendige, fehleranfällige manuelle Anpassen von Schwellenwerten entfällt komplett, wodurch sich das Team wieder auf strategische Aufgaben fokussieren kann.
- Proaktiver, always-on Schutz für mehr Sicherheit und Kontrolle: Moderner DDoS-Schutz muss Angriffe stoppen, bevor sie die Netzwerkleistung oder die Verfügbarkeit von Diensten beeinträchtigen können. Ein proaktiver, always-on Schutz erkennt bösartigen Datenverkehr frühzeitig und wehrt ihn an der Quelle ab, bevor er den legitimen Datenverkehr stören kann. Dies Hilf Unternehmen, auch bei schnell ablaufenden Angriffen eine stabile Leistung, kontinuierliche Verfügbarkeit und volle Kontrolle aufrechtzuerhalten.
- Forensische Transparenz statt Black-Box: Wenn Traffic blockiert wird, brauchen Sicherheitsteams sofortige Klarheit. Eine moderne Abwehrarchitektur ersetzt die Black-Box durch forensische Sichtbarkeit in Echtzeit. Anhand von detaillierten Live-Dashboards, spezifischen „Reason Codes“ und Echtzeit-Logs können Security-Teams jederzeit exakt und auditsicher nachvollziehen, auf welcher Basis eine Mitigationsentscheidung getroffen wurde.
Die neue Ära der DDoS-Abwehr
In einer Zeit, in der Uptime gleichbedeutend mit Umsatz und Reputation ist, darf Cybersicherheit den Geschäftsbetrieb nicht behindern. Mit intelligenter Network DDoS-Mitigation müssen Unternehmen sich nicht mehr zwischen maximalem Schutz und optimaler User Experience entscheiden. Wer auf verhaltensbasierte, transparente und granulare Abwehrmechanismen setzt, stellt sicher, dass Netzwerke nicht nur vor Bedrohungen geschützt sind, sondern für legitime Nutzer jederzeit offen bleiben.
Das könnte Ihnen auch gefallen:


