
Nicht alle Angriffe sind spektakulär. Manche verlaufen eher unscheinbar, ohne dabei Rekordwerte bei Bandbreite oder Paketvolumen zu erreichen. So auch die folgende DDoS-Attacke: Auf den ersten Blick wirkt er eher unspektakulär, da das Volumen bei rund drei Millionen Requests lag. Im Vergleich zu groß angelegten DDoS-Kampagnen ist dies kein außergewöhnlicher Wert. Dennoch lohnt sich ein genauerer Blick auf die Struktur. Denn diese zeigt, wie Angreifer selbst mit begrenzten Mitteln versuchen, Webanwendungen gezielt zu stören.
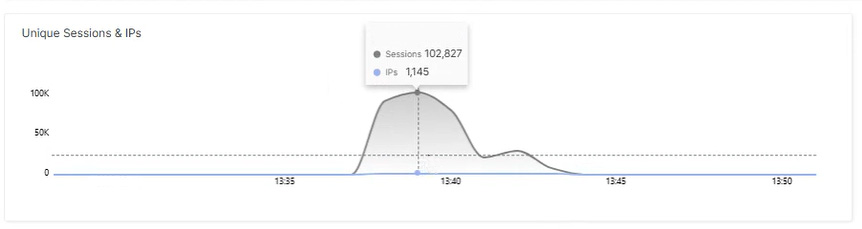
Auffälliges Traffic-Muster: langsamer Anstieg, plötzlicher Peak
Der Traffic-Verlauf zeigte zunächst einen langsamen, kontinuierlichen Anstieg der Anfragen. Danach folgte ein einzelner, deutlich sichtbarer Peak. Im Gegensatz zu massiven volumetrischen Angriffen blieb das Gesamtvolumen jedoch moderat.

Charakteristisch war zudem, dass sich der Angriff ausschließlich auf die Root-Domain, also die Startseite der Website, konzentrierte und nicht auf spezifische Unterverzeichnisse oder API-Endpunkte. Solche Muster sind typisch für vereinfachte Botnet-Aktivitäten, bei denen keine gezielte Analyse von Anwendungspunkten erfolgt, sondern generische Anfragen an den Hauptendpunkt gesendet werden.
Geografische Einschränkung als Schutzmaßnahme
In diesem Fall war die bestehende Zugriffsbeschränkung ein wesentlicher Faktor: Für die betroffenen Domains war eine Regel aktiv, die nur Traffic aus bestimmten Regionen zuließ, wie etwa den USA und Europa. Anfragen aus anderen Ländern wurden automatisch blockiert. Ein großer Teil des Angriffsverkehrs stammte jedoch aus Ländern, die nicht auf der Whitelist standen, darunter China, Indien oder die Türkei. Diese Requests wurden unmittelbar verworfen.
Gleichzeitig wurde ein Teil des Traffics aus zugelassenen Ländern wie Deutschland blockiert. Die Ursache lag dabei nicht in der Geofilterung, sondern in anderen Schutzmechanismen wie dem Rate-Limiting.

Rate Limiting: Schutz vor zu vielen Anfragen
Rate-Limiting ist eine gängige Methode, um Webanwendungen abzusichern. Dabei wird festgelegt, wie viele Anfragen ein Client innerhalb eines bestimmten Zeitfensters stellen darf. Wird diese Schwelle von einer IP-Adresse überschritten, werden weitere Requests temporär blockiert.
Im vorliegenden Fall zeigte sich, dass ein Großteil der zugelassenen deutschen Anfragen aus genau diesem Grund abgewiesen wurde. Dies deutet darauf hin, dass die betreffenden IP-Adressen in kurzer Zeit ungewöhnlich viele Requests generierten. Ein typisches Muster für automatisierte Botanfragen.
GET-Request im Fokus
Zudem wurden auch HTTP-Anfragen mit der Methode GET blockiert. Das wirft zunächst Fragen auf, da GET die am häufigsten genutzte HTTP-Methode ist.
Um dies einzuordnen, lohnt sich ein kurzer Blick auf die Grundlagen des HTTP-Protokolls.
HTTP (Hypertext Transfer Protocol) definiert verschiedene Methoden, mit denen Clients (z. B. Browser) mit einem Webserver kommunizieren. Zu den wichtigsten zählen:
- GET: Ruft Informationen vom Server ab
- POST: Sendet Daten an den Server (z. B. Formulareingaben).
- PUT: Aktualisiert bestehende Ressourcen.
- DELETE: Löscht Ressourcen.
- HEAD: Fordert nur Header-Informationen an.
Die GET-Methode dient ausschließlich dazu, Informationen vom Server zu erhalten. Ein klassischer Seitenaufruf im Browser ist technisch gesehen ein GET-Request. Dabei werden keine Daten verändert oder gespeichert, sondern lediglich eine Ressource abgefragt.
Genau deshalb gilt GET grundsätzlich als „harmlos“: Über einen reinen GET-Request lassen sich keine Daten auf dem Server verändern oder direkt einschleusen. Injection-Angriffe zielen typischerweise auf Parameter oder andere Schwachstellen ab, nicht auf die Methode selbst.
Warum GET dennoch blockiert wird
Es kann sinnvoll sein, GET-Anfragen gezielt zu blockieren, wenn eine Anwendung diese nicht benötigt. In spezialisierten APIs oder Backend-Systemen, die ausschließlich POST-Anfragen erwarten, kann das Blockieren aller GET-Anfragen die Angriffsfläche reduzieren. Hier war ein solcher Filter aktiv. Alle GET-Anfragen wurden automatisch verworfen.
Da der beobachtete Angriff ausschließlich mit der GET-Methode arbeitete und nur die Root-Domain ansprach, wurde der Verkehr vollständig abgefangen. Es handelte sich also um eine einfache, massenhafte Nutzung der Standardmethode, um Serverressourcen zu binden.
Erfahren Sie mehr über eine einfach zu implementierende und äußerst effektive WAAP-Lösung.
Alles aus einer Hand und auf Wunsch als vollständig verwalteter Service.
Kleine Botnetze, reale Auswirkungen
Im Gegensatz zu großen Botnetzen handelte es sich um ein kleines Netz mit einer geringen Anzahl beteiligter IP-Adressen. Das bedeutet jedoch nicht, dass kein Risiko besteht.
Ob ein Angriff erfolgreich ist, hängt auch von der Zielinfrastruktur ab. Eine ressourcenintensive Webanwendung oder ein schlecht skalierter Server kann bereits durch moderate Request-Zahlen überlastet werden.
Besonders bei vielen gleichzeitigen Verbindungen oder der Generierung dynamischer Inhalte steigt die CPU- und Speicherbelastung schnell an. Solche Angriffe zielen auf Anwendungsebene. Sie versuchen, Serverressourcen durch viele HTTP-Anfragen zu binden.
GET-Anfragen sind alltäglich, weshalb sie nicht pauschal als bösartig klassifiziert werden können. Erst in Kombination mit Frequenz, Herkunft und Verhaltensmustern entsteht ein belastbares Bild. Der Vorfall verdeutlicht, dass nicht die Größe des Botnetzes, sondern die Wechselwirkung zwischen Angriffsstrategie und Zielarchitektur über das Risiko entscheidet.
Ein kleiner, sauber strukturierter Angriff kann dennoch Wirkung entfalten, insbesondere bei fehlenden Schutzmechanismen. In diesem Fall blieben sie wirksam.
Haben Sie Fragen zum Thema oder brauchen Informationen, wie Sie sich ideal auf solche Angriffe vorbereiten können?
Jetzt unsere Cyberexperten kontaktieren>>
Das könnte Ihnen auch gefallen:





