
Not all attacks are spectacular. Some are rather inconspicuous, without reaching record levels of bandwidth or packet volume. This was the case with the following DDoS attack: At first glance, it seemed rather unspectacular, as the volume was around 3 million requests. Compared to large-scale DDoS campaigns, this is not an exceptional figure. Nevertheless, it is worth taking a closer look at the structure, as it shows how attackers try to disrupt web applications in a targeted manner, even with limited resources.
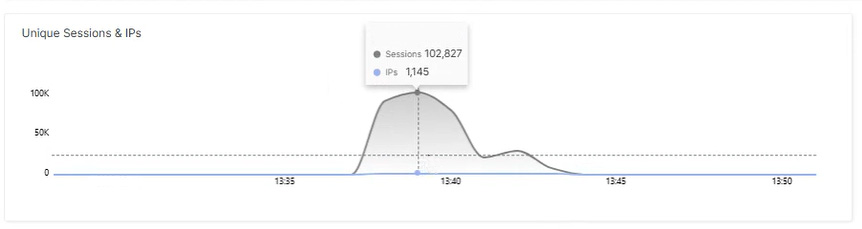
Conspicuous traffic pattern: slow increase, sudden peak
The traffic curve initially showed a slow, continuous increase in requests. This was followed by a single, clearly visible peak. In contrast to massive volumetric attacks, however, the total volume remained moderate.

Another characteristic feature was that the attack focused exclusively on the root domain, i.e., the website’s home page, and not on specific subdirectories or API endpoints. Such patterns are typical of simplified botnet activities, in which no targeted analysis of application points is performed, but rather generic requests are sent to the main endpoint.
Geographical restriction as a protective measure
In this case, the existing access restriction was a key factor: a rule was active for the affected domains that only allowed traffic from certain regions, such as the US and Europe. Requests from other countries were automatically blocked. However, a large part of the attack traffic originated from countries that were not on the whitelist, including China, India, and Turkey. These requests were immediately rejected.
Some of the traffic from approved countries (such as Germany) was blocked. The cause was not geofiltering, but other protective mechanisms such as rate limiting.

Rate limiting: protection against too many requests
Rate limiting is a common method of securing web applications. It specifies how many requests a client is allowed to make within a certain time window. If this threshold is exceeded by an IP address, further requests are temporarily blocked.
In this case, it became apparent that a large proportion of the approved German requests were rejected for precisely this reason. This indicates the IP addresses in question generated an unusually high number of requests in a short period of time, which is a typical pattern for automated bot requests.
We took IP as an example and this case was linked to the IP, but rate limit can be connected to any HTTP parameters, such as unique Header, Cookie or Argument.
Focus on GET requests
HTTP requests using the GET method were also blocked. This initially raises questions, as GET is the most commonly used HTTP method.
To understand why, it is worth taking a brief look at the basics of the HTTP protocol.
HTTP (Hypertext Transfer Protocol) defines various methods that clients (e.g., browsers) use to communicate with a web server. The most important ones include:
• GET: Retrieves information from the server.
• POST: Sends data to the server (e.g., form entries).
• PUT: Updates existing resources.
• DELETE: Deletes resources.
• HEAD: Requests header information only.
The GET method is used exclusively to obtain information from the server. From a technical perspective, a classic page view in a browser is a GET request. No data is changed or stored; only a resource is queried.
This is precisely why GET is generally considered “harmless”: a pure GET request cannot be used to change or directly inject data on the server. Injection attacks typically target parameters or other vulnerabilities, not the method itself.
Why GET is still blocked
It can be useful to block GET requests if an application does not need them. In specialized APIs or backend systems that only expect POST requests, blocking all GET requests can reduce the available attack surface. Such a filter was active here, meaning all GET requests were automatically discarded.
Learn more about an easy-to-implement and highly effective WAAP solution.
Everything from a single source, and available as a fully managed service upon request.
Since the observed attack worked exclusively with the GET method and only addressed the root domain, the traffic was completely intercepted. It was therefore a simple, mass use of the standard method to tie up server resources.
Small botnets, real impact
In contrast to large botnets, this was a small network with a small number of IP addresses involved. However, that does not mean that there is no risk.
Whether an attack is successful also depends on the target infrastructure. A resource-intensive web application or a poorly scaled server can be overloaded even by a moderate number of requests.
CPU and memory load increases rapidly, especially with many simultaneous connections or the generation of dynamic content. Such attacks target the application level and attempt to tie up server resources with many HTTP requests.
GET requests are commonplace, which is why they cannot be classified as malicious across the board. Only in combination with frequency, origin, and behavior patterns does a reliable picture emerge. The incident illustrates that it is not the size of the botnet, but the interaction between the attack strategy and the target architecture that determines the risk.
A small, cleanly structured attack can still be effective, especially if there are no protective mechanisms in place. In this case, though, the protective mechanisms worked exactly as intended.
Do you have any questions about this topic, or would you like information on how best to prepare for such attacks?
