
Ein zweistufiger DDoS-Angriff mit einer Bandbreite von über einem Terabit und gezielten Zugriffsversuchen auf die Bereiche Login, Download und Admin zeigt: Moderne Angreifer testen die Systeme nicht vor, sondern auch während eines Angriffs.
Es gab zwei Angriffswellen mit einer zehnstündigen Pause dazwischen. Insgesamt wurden über 335 Millionen Requests gesendet. Darunter gezielte Versuche um sich in Login-Bereiche einzuloggen, Dateien herunterzuladen und WordPress-Admin-Zugänge zu finden. Was auf den ersten Blick wie eine klassische volumetrische DDoS-Attacke aussieht, entpuppt sich bei näherer Analyse als hybride Attacke: Lärm als Ablenkung, Infiltrationsversuche als eigentliches Ziel.
Erste Welle: Über einem Terabit und trotzdem kaum Schäden
Der erste Spike war massiv. Es gab mehr als ein Terabit Bandbreite, rund 25.000 Requests pro Sekunde und knapp 60 Millionen parallele Sessions im Spitzenwert. Die Quell-IPs ließen sich überwiegend großen Cloud-Anbietern und Hosting-Providern zuordnen. Es handelte sich also nicht um ein diffuses IoT-Botnetz, sondern um konzentrierte Serverkapazität. Die Web Application Firewall blockte allerdings den überwältigenden Großteil der Requests: Weniger als 58.000 Requests erreichten den Origin-Server.
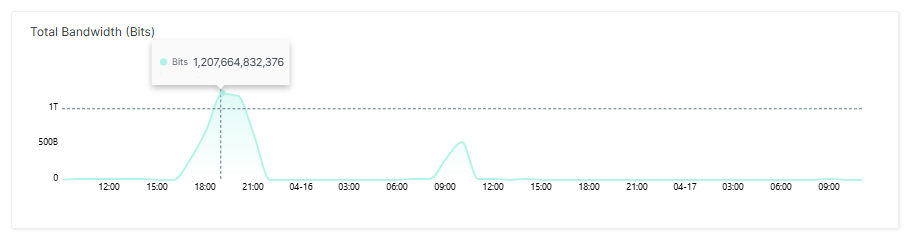
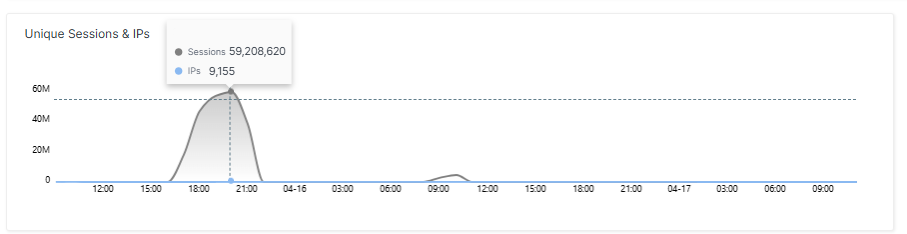
Technisch war der Angriff kein Meisterwerk. Es handelte sich um einen Layer-7-HTTP-Flood mit synthetisch rotierenden User-Agents. Die entscheidende Frage ist jedoch eine andere: Warum haben 10.000 unterschiedliche IP-Adressen zusammen fast 60 Millionen Sessions erzeugt? Weil es sich bei den dahinterliegenden Maschinen um ressourcenstarke Geräte wie Server handelte – nicht um Heimrouter oder Kameras. Solche Cloud-Instanzen können Hundertausende parallele Verbindungen aufbauen. Ein IoT-Gerät schafft das nicht. Am Ende ist es eine Frage der Rechenleistung.
Erfahren Sie mehr über eine einfach zu implementierende und äußerst effektive WAAP-Lösung.
Alles aus einer Hand und auf Wunsch als vollständig verwalteter Service.
Kein reiner DDoS – gezielte Zugriffsversuche auf sensible Bereiche
Was diesen Angriff von einem gewöhnlichen Überlastungsangriff unterscheidet, zeigt sich in der URL-Verteilung der Requests. Die Angreifer haben nicht blind den Root-Pfad bombardiert. Stattdessen haben sie gezielt Download-Seiten zugegriffen, Login-Formulare mit Anfragen geflutet und versucht, den WordPress-Admin-Bereich zu erreichen. Content-Filter haben keine SQL-Injection– oder XSS-Muster registriert. Offenbar wollten die Angreifer keine Sicherheitslücken ausnutzen, sondern durch eine hohe Anzahl von Anfragen Zugänge erzwingen: Brute-Force unter dem Deckmantel eines DDoS-Angriffs.
Angegriffene Bereiche:
- Root-Domain (Hauptlast)
- Download-/Content-Seiten
- Login-Formular
- WordPress-Admin-Pfad
Technische Signatur des Angriffs:
- Layer-7-HTTP-Flood
- Synthetische User-Agents
- Keine SQLi oder XSS-Verusche
- Brute-Force-Muster auf Login-Bereich
Eine Besonderheit, die wir gesehen haben: aus über 300.000 Requests konnte sich genau ein einziger Request an der WAF vorbeischmuggeln. Das ist kein Fehler in der Konfiguration, sondern ein statistischer Effekt, der auftritt, wenn Tausende legitim wirkende Cloud-IPs jeweils wenige Anfragen senden. Eine davon rutscht durch, bevor die Rate-Limiting-Regel greift. Das klingt nach einer Kleinigkeit. In der Praxis bedeutet es jedoch: Angreifer mit genügend verteilten Ressourcen können Mitigation-Systeme auch ohne direkten Bypass-Exploit systematisch aushöhlen.
Zweite Welle: kleiner, aber mit gestiegener Latenz
Zehn Stunden nach dem ersten Spike folgte ein zweiter Angriff mit einem Volumen von rund 500 Gbit/s. Er war kleiner als der erste, hatte aber eine interessante Wirkung. Die Latenz war beim zweiten Spike höher als beim ersten, obwohl der Angriff schwächer war. Der Grund: Die Requests pro Sekunde konzentrierten sich beim zweiten Spike auf das eigene System, die CPU-Auslastung stieg schneller und die automatische Skalierung hatte weniger Zeit zum Reagieren.
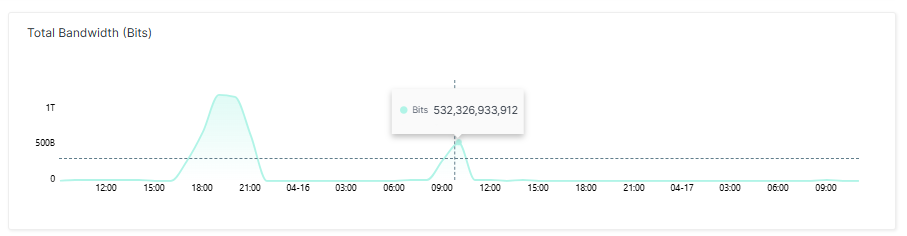
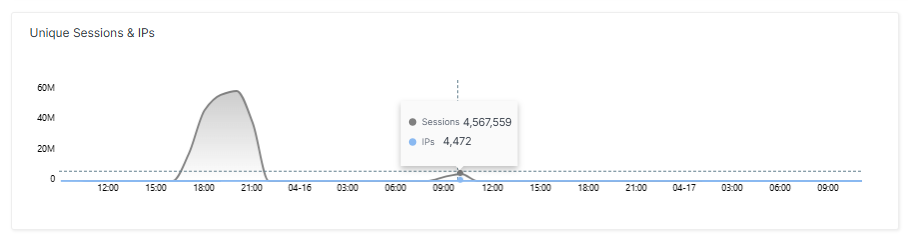
Dies verdeutlicht eine oft unterschätzte Wahrheit über DDoS-Mitigation: Bandbreite ist nicht der einzige Stressfaktor. Anfragen pro Sekunde belasten die CPU unabhängig von der übertragenen Datenmenge. Wer nur auf Bandbreiten-Schwellwerte schaut, übersieht, wann ein System tatsächlich in die Knie geht.
Der zweite Angriff war halb so groß, aber intensiver in Bezug auf die Latenz. Warum? Weil nicht die Bandbreite, sondern die Anzahl der Requests pro Sekunde die CPU-Last bestimmt. Ein kleinerer Angriff kann somit mehr spürbaren Schaden anrichten als ein größerer, wenn er die richtigen Engpässe trifft.
Cloud-Missbrauch: Ein strukturelles Problem
Die Herkunft des Traffics wirft eine unbequeme Frage auf. Nahezu alle größeren IP-Blöcke, die für Angriffe genutzt wurden, gehören zu bekannten Cloud- und Hosting-Anbietern. Diese IPs stehen in vielen Systemen auf Whitelists, was nicht auf Nachlässigkeit zurückzuführen ist, sondern darauf, dass legitime Dienste regelmäßig über genau diese Adressen kommunizieren. Wer einen Traffic-Filter baut, der zum Beispiel Microsoft-IPs grundsätzlich blockiert, schließt damit auch einen Großteil des normalen Traffics aus.
Genau das ist das strukturelle Problem: Cloud-Infrastruktur ist günstig, anonym buchbar und technisch vertrauenswürdig. Die Frage, ob diese Ressourcen gekauft, gemietet oder kompromittiert wurden, ist aus Verteidigerperspektive fast zweitrangig. Tatsache ist, dass Angriffe in diesem Umfang – über ein Terabit, hunderte Millionen Requests – mittlerweile monatlich auftreten. Vor zwei Jahren waren solche Angriffe deutlich seltener.
Verhaltensbasierte Erkennung schlägt IP-Reputation. Wer nur auf bekannte „Bad Actors” wartet, läuft der Realität hinterher. Entscheidend ist, anomales Verhalten auf Applikationsebene frühzeitig zu identifizieren. Unabhängig davon, aus welchem Rechenzentrum der Traffic stammt.
Sie haben Fragen, wie Sie sich effektiv gegen Cyberangriffe schützen können? Unsere Sicherheitsexperten stehen Ihnen jederzeit rund um die Uhr zur Verfügung.
Jetzt kontaktieren >>
Das könnte Ihnen auch gefallen:





